文章詳情頁
python - 用sklearn求大文本的tfidf特征?
瀏覽:202日期:2022-06-27 15:50:07
問題描述
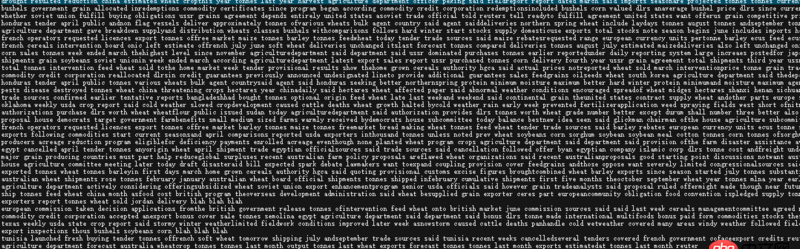 上面的數據是從reuters數據集中取得7303個訓練集,用sklearn對其取tfidf特征,得到的結果都是0,這是怎么回事?
上面的數據是從reuters數據集中取得7303個訓練集,用sklearn對其取tfidf特征,得到的結果都是0,這是怎么回事?
當我從這些數據中取一部分時,對于這些少部分數據能夠得到正確的tfidf結果。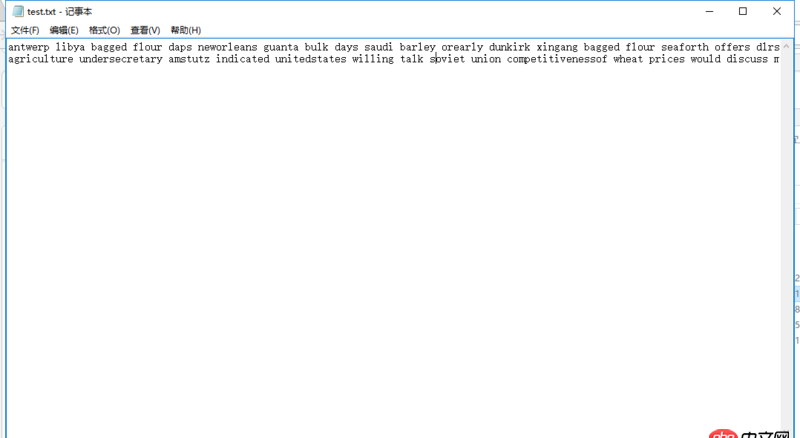

問題解答
回答1:上代碼,可能是你精度太低或者min_count導致的
比如詞頻是1,總詞數1e9,對應的tf就是1e-9,被忽略了。
相關文章:
1. html5 - datatables 加載不出來數據。2. node.js - mongodb查找子對象的名稱為某個值的對象的方法3. 測試自動化html元素選擇器元素ID或DataAttribute [關閉]4. html5和Flash對抗是什么情況?5. 利用IPMI遠程安裝centos報錯!6. javascript - QQ第三方登錄的問題7. 在mac下出現了兩個docker環境8. 運行python程序時出現“應用程序發生異常”的內存錯誤?9. spring-mvc - spring-session-redis HttpSessionListener失效10. 正在使用electron和node.js做桌面應用,需要實時監聽是否有網絡連接,node或者electron是否可以做到
排行榜

 網公網安備
網公網安備