網頁爬蟲 - python 爬蟲怎么處理json內容
問題描述
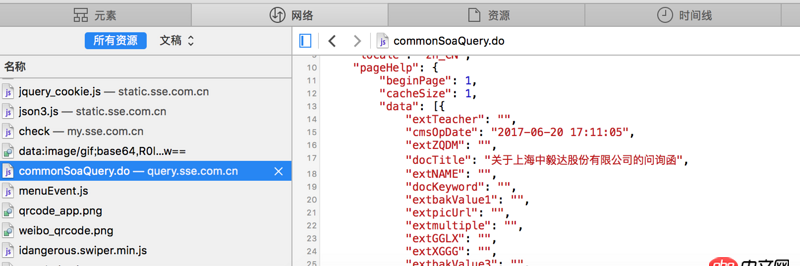
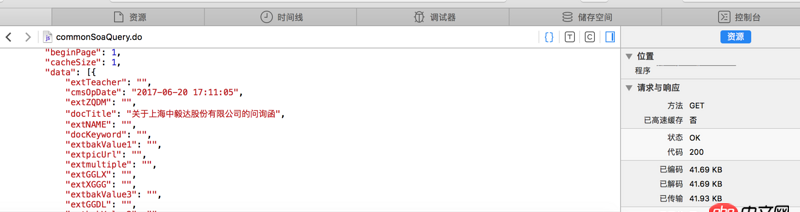
看不清的話 網站地址是http://www.sse.com.cn/disclos...紅字是我需要的內容 但是我提取不出來求教怎么操作
問題解答
回答1:import requestsurl = ’http://query.sse.com.cn/commonSoaQuery.do?siteId=28&sqlId=BS_GGLL&extGGLX=&stockcode=&channelId=10743%2C10744%2C10012&extGGDL=&order=createTime%7Cdesc%2Cstockcode%7Casc&isPagination=true&pageHelp.pageSize=15&pageHelp.pageNo=1&pageHelp.beginPage=1&pageHelp.cacheSize=1&pageHelp.endPage=5’headers = { ’Referer’:’http://www.sse.com.cn/disclosure/credibility/supervision/inquiries/’, ’User-Agent’:’Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36’}r = requests.get(url, headers=headers)print r.json()[’result’]回答2:
import requestsurl = ’http://query.sse.com.cn/commonSoaQuery.do?siteId=28&sqlId=BS_GGLL&extGGLX=&stockcode=&channelId=10743%2C10744%2C10012&extGGDL=&order=createTime%7Cdesc%2Cstockcode%7Casc&isPagination=true&pageHelp.pageSize=15&pageHelp.pageNo=1&pageHelp.beginPage=1&pageHelp.cacheSize=1&pageHelp.endPage=5&_=1498029409382’session = requests.session()session.headers.update({ ’Referer’: ’http://www.sse.com.cn/disclosure/credibility/supervision/inquiries/’, ’User-Agent’: ’Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36’})result = session.get(url).json()print result
相關文章:
1. html5和Flash對抗是什么情況?2. html5 - datatables 加載不出來數據。3. docker 下面創建的IMAGE 他們的 ID 一樣?這個是怎么回事????4. 利用IPMI遠程安裝centos報錯!5. node.js - mongodb查找子對象的名稱為某個值的對象的方法6. 運行python程序時出現“應用程序發生異常”的內存錯誤?7. 測試自動化html元素選擇器元素ID或DataAttribute [關閉]8. javascript - QQ第三方登錄的問題9. javascript - 在 model里定義的 引用表模型時,model為undefined。10. spring-mvc - spring-session-redis HttpSessionListener失效

 網公網安備
網公網安備