文章詳情頁(yè)
python - 使用scrapy框架爬百度圖片被墻
瀏覽:209日期:2022-06-30 14:19:37
問(wèn)題描述
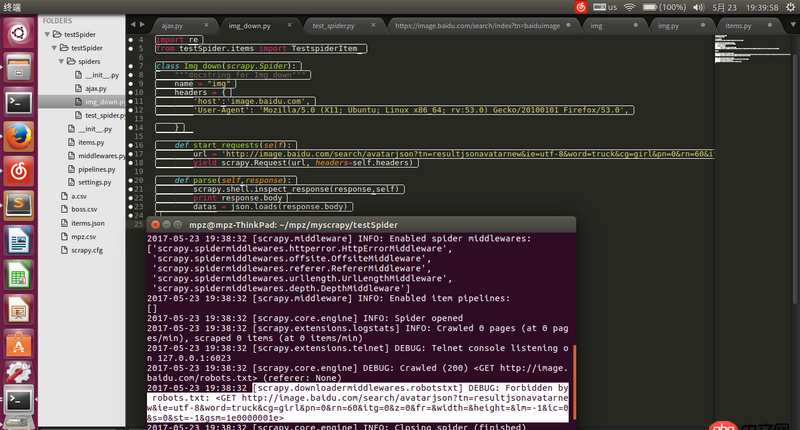
請(qǐng)求地址url是通過(guò)firefox查看得到的json的地址,用瀏覽器可以打開(kāi),但是用scrapy爬的時(shí)候就被ban了求解決辦法。
https://image.baidu.com/searc...
問(wèn)題解答
回答1:在 settings.py 將 ROBOTSTXT_OBEY = False 試試。
回答2:不要加hearders試試
回答3:贊成樓上,如果還會(huì)被墻。可采用scrapy+selenium+phantomjs的方式。
相關(guān)文章:
1. debian - docker依賴(lài)的aufs-tools源碼哪里可以找到啊?2. 為什么我ping不通我的docker容器呢???3. vim - docker中新的ubuntu12.04鏡像,運(yùn)行vi提示,找不到命名.4. docker網(wǎng)絡(luò)端口映射,沒(méi)有方便點(diǎn)的操作方法么?5. docker-compose 為何找不到配置文件?6. mac連接阿里云docker集群,已經(jīng)卡了2天了,求問(wèn)?7. docker安裝后出現(xiàn)Cannot connect to the Docker daemon.8. golang - 用IDE看docker源碼時(shí)的小問(wèn)題9. docker images顯示的鏡像過(guò)多,狗眼被亮瞎了,怎么辦?10. Android和JS的交互問(wèn)題
排行榜
熱門(mén)標(biāo)簽
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備