Python爬蟲如何爬取span和span中間的內容并分別存入字典里?
問題描述
我想把房屋概況分別抓出來并分別作為獨立的列存儲進字典里,但是行內元素沒有辦法直接用for循環摳出來。這是我的代碼:
soup.select(’.house-info li’)[1].text.strip()
這是網頁html代碼:
<li><span class='info-tit'>房屋概況:</span>住宅<span class='splitline'>|</span>1室1廳1衛<span class='splitline'>|</span><span>46m2</span><span class='splitline'>|</span> (高層)/共18層<span class='splitline'>|</span>南北<span class='splitline'>|</span> 豪華裝修 </li>
問題解答
回答1:其實還是很有簡單的,你看這個還是有規律的,規律在于有分隔符|,我寫了個DEMO
something = ’’’<li><span class='info-tit'>房屋概況:</span>住宅 <span class='splitline'>|</span>1室1廳1衛<span class='splitline'>|</span><span>46m2</span><span class='splitline'>|</span> (高層)/共18層<span class='splitline'>|</span>南北<span class='splitline'>|</span> 豪華裝修 </li>’’’;soup = BeautifulSoup(something, ’lxml’)plaintext = soup.select(’li’)[0].get_text().strip()
通過get_text()得到內在所有內容,然后去除空格。后面你就用split進行分割吧,后面的不寫了。如果有問題再交流。
回答2:我感覺這個html代碼寫錯了呢,標簽的內容文本在標簽外面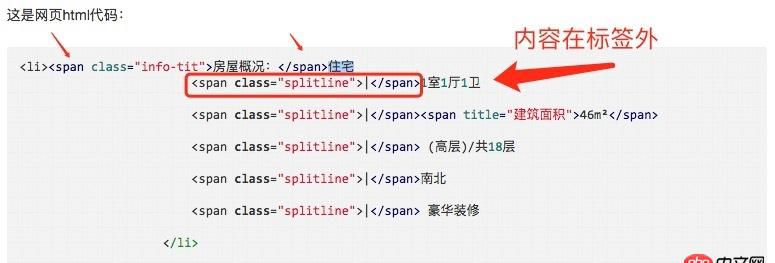
房屋概況:
46m2
回答3:innerText
回答4:你這種情況,我覺得用 for 循環加上正則表達式是最方便的,如果所有模版都是這樣固定的話
回答5:用pyquery吧
from pyquery import PyQuery as Q
Q(text).find(’.house-info li’).text()
相關文章:
1. html5和Flash對抗是什么情況?2. html5 - datatables 加載不出來數據。3. docker 下面創建的IMAGE 他們的 ID 一樣?這個是怎么回事????4. 利用IPMI遠程安裝centos報錯!5. node.js - mongodb查找子對象的名稱為某個值的對象的方法6. 運行python程序時出現“應用程序發生異常”的內存錯誤?7. 測試自動化html元素選擇器元素ID或DataAttribute [關閉]8. javascript - QQ第三方登錄的問題9. javascript - 在 model里定義的 引用表模型時,model為undefined。10. spring-mvc - spring-session-redis HttpSessionListener失效

 網公網安備
網公網安備