文章詳情頁
網(wǎng)頁爬蟲 - Python爬蟲返回狀態(tài)碼與實際情況不符?
瀏覽:303日期:2022-09-03 18:57:11
問題描述
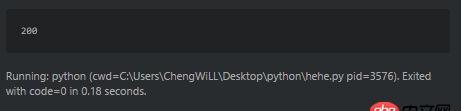
import urllib2opener = urllib2.build_opener()html = Noneresponse = Noneresponse = opener.open(’http://www.sxxrcs.com/was5/web/’)html = response.codeprint html
比如這個爬蟲,輸出狀態(tài)碼是200。
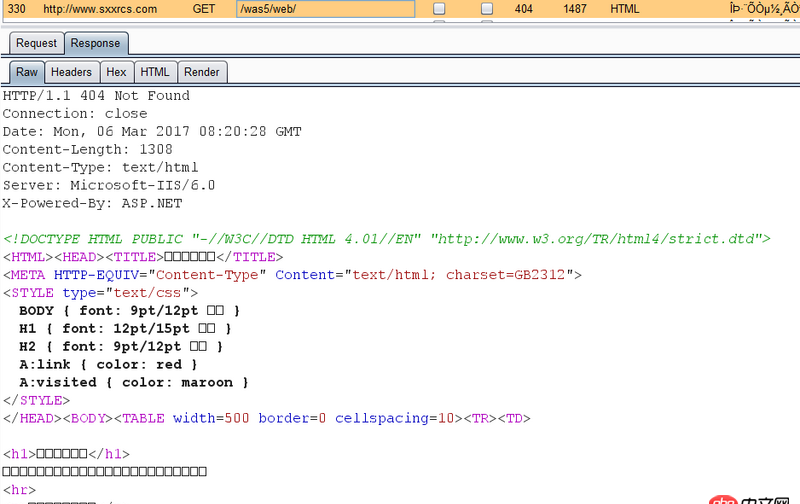
可是直接訪問http://www.sxxrcs.com/was5/web/是404,抓包響應(yīng)的也是404,請問這是為什么?
問題解答
回答1:用requests吧
import requestsr = requests.get(’http://www.sxxrcs.com/was5/web/’)print r.status_codeprint r.text回答2:
200正常啊,requests方便快捷。
相關(guān)文章:
1. node.js - nodejs+express+vue2. javascript - 我的站點貌似被別人克隆了, google 搜索特定文章,除了域名不一樣,其他的都一樣,如何解決?3. java - web端百度網(wǎng)盤的一個操作為什么要分兩次請求服務(wù)器, 有什么好處嗎4. 數(shù)據(jù)庫 - Mysql的存儲過程真的是個坑!求助下面的存儲過程哪里錯啦,實在是找不到哪里的問題了。5. javascript - 如何獲取未來元素的父元素在頁面中所有相同元素中是第幾個?6. python - 如何把152753這個字符串轉(zhuǎn)變成時間格式15:27:537. 使用mysql命令行連接遠程數(shù)據(jù)庫host跳轉(zhuǎn)8. javascript - onclick事件點擊不起作用9. javascript - webpack-dev-server和webpack沖突嗎10. python 字符串匹配問題
排行榜

熱門標簽
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備