Python統計文本詞匯出現次數的實例代碼
問題描述
有時在遇到一個文本需要統計文本內詞匯的次數 的時候 ,可以用一個簡單的python程序來實現。
解決方案
首先需要的是一個文本文件(.txt)格式(文本內詞匯以空格分隔),因為需要的是一個程序,所以要考慮如何將文件打開而不是采用復制粘貼的方式。這時就要用到open()的方式來打開文檔,然后通過read()讀取其中內容,再將詞匯作為key,出現次數作為values存入字典。
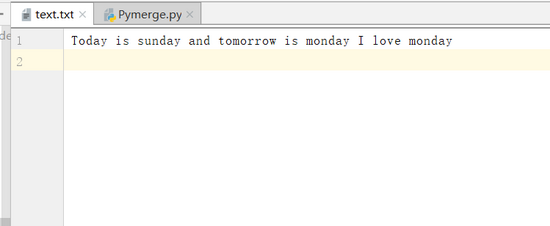
圖 1 txt文件內容
再通過open和read函數來讀取文件:
open_file=open('text.txt')file_txt=open_file.read()
然后再創建一個空字典,將所有出現的每個詞匯作為key保存到字典中,對文本從開始到結束,循環處理每個詞匯,并將詞匯設置為一個字典的key,將其value設置為1,如果已經存在該詞匯的key,說明該詞匯已經使用過,就將value累積加1。
代碼示例:
def wordcount(readtxt):readlist = readtxt.split()dict1={}for every_world in readlist:if every_world in dict1:dict1[every_world] += 1else:dict1[every_world] = 1return dict1print(wordcount(file_txt))
這里加了def函數把該程序封裝成一個函數。 最后輸出得到詞匯出現的字典:
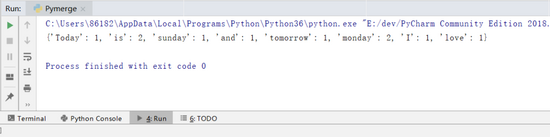
圖 2 形成字典
ps:下面看下python統計文本中每個單詞出現的次數
1.python統計文本中每個單詞出現的次數:
#coding=utf-8__author__ = ’zcg’import collectionsimport oswith open(’abc.txt’) as file1:#打開文本文件 str1=file1.read().split(’ ’)#將文章按照空格劃分開print '原文本:n %s'% str1print 'n各單詞出現的次數:n %s' % collections.Counter(str1)print collections.Counter(str1)[’a’]#以字典的形式存儲,每個字符對應的鍵值就是在文本中出現的次數
2.python編寫生成序列化:
__author__ = ’zcg’#endcoding utf-8import string,randomfield=string.letters+string.digitsdef getRandom(): return ''.join(random.sample(field,4))def concatenate(group): return '-'.join([getRandom() for i in range(group)])def generate(n): return [concatenate(4) for i in range(n)]if __name__ ==’__main__’: print generate(10)
3.遍歷excel表格中的所有數據:
__author__ = ’Administrator’import xlrdworkbook = xlrd.open_workbook(’config.xlsx’)print 'There are {} sheets in the workbook'.format(workbook.nsheets)for booksheet in workbook.sheets(): for col in xrange(booksheet.ncols): for row in xrange(booksheet.nrows): value=booksheet.cell(row,col).value print value
其中xlrd需要百度下載導入這個模塊到python中
4.將表格中的數據整理成lua類型的一個格式
#coding=utf-8__author__ = ’zcg’#2017 9/26import xlrdfileOutput = open(’Configs.lua’,’w’)writeData='--@author:zcgnnn'workbook = xlrd.open_workbook(’config.xlsx’)print 'There are {} sheets in the workbook'.format(workbook.nsheets)for booksheet in workbook.sheets(): writeData = writeData+’AT’ +booksheet.name+’ ={n’ for col in xrange(booksheet.ncols): for row in xrange(booksheet.nrows): value = booksheet.cell(row,col).value if row ==0: writeData = writeData+’t’+’['’+value+’']’+’=’+’{’ else: writeData=writeData+’'’+str(booksheet.cell(row,col).value)+’', ’ else: writeData=writeData+’},n’ else: writeData=writeData+’}nn’else : fileOutput.write(writeData)fileOutput.close()
總結
到此這篇關于Python統計文本詞匯出現次數的實例代碼的文章就介紹到這了,更多相關Python統計文本詞匯出現次數內容請搜索好吧啦網以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持好吧啦網!
相關文章:
1. spring-mvc - spring-session-redis HttpSessionListener失效2. html5和Flash對抗是什么情況?3. 運行python程序時出現“應用程序發生異常”的內存錯誤?4. javascript - QQ第三方登錄的問題5. node.js - mongodb查找子對象的名稱為某個值的對象的方法6. 測試自動化html元素選擇器元素ID或DataAttribute [關閉]7. 在mac下出現了兩個docker環境8. 利用IPMI遠程安裝centos報錯!9. javascript - 在 model里定義的 引用表模型時,model為undefined。10. 淺談Vue使用Cascader級聯選擇器數據回顯中的坑

 網公網安備
網公網安備