Python 爬蟲批量爬取網(wǎng)頁圖片保存到本地的實(shí)現(xiàn)代碼
其實(shí)和爬取普通數(shù)據(jù)本質(zhì)一樣,不過我們直接爬取數(shù)據(jù)會直接返回,爬取圖片需要處理成二進(jìn)制數(shù)據(jù)保存成圖片格式(.jpg,.png等)的數(shù)據(jù)文本。
現(xiàn)在貼一個url=https://img.ivsky.com/img/tupian/t/201008/05/bianxingjingang-001.jpg請復(fù)制上面的url直接在某個瀏覽器打開,你會看到如下內(nèi)容:
這就是通過網(wǎng)頁訪問到的該網(wǎng)站的該圖片,于是我們可以直接利用requests模塊,進(jìn)行這個圖片的請求,于是這個網(wǎng)站便會返回給我們該圖片的數(shù)據(jù),我們再把數(shù)據(jù)寫入本地文件就行,比較簡單。
import requestsheaders={ ’user-agent’: ’Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3861.400 QQBrowser/10.7.4313.400’}url=’https://img.ivsky.com/img/tupian/t/201008/05/bianxingjingang-001.jpg’re=requests.get(url,headers=headers)print(re.status_code)#查看請求狀態(tài),返回200說明正常path=’test.jpg’#文件儲存地址with open(path, ’wb’) as f:#把圖片數(shù)據(jù)寫入本地,wb表示二進(jìn)制儲存 for chunk in re.iter_content(chunk_size=128):f.write(chunk)
然后得到test.jpg圖片,如下

點(diǎn)擊打開查看如下:
便是下載成功辣,很簡單吧。
現(xiàn)在分析下批量下載,我們將上面的代碼打包成一個函數(shù),于是針對每張圖片,單獨(dú)一個名字,單獨(dú)一個圖片文件請求,于是有如下代碼:
import requestsdef get_pictures(url,path): headers={ ’user-agent’: ’Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3861.400 QQBrowser/10.7.4313.400’} re=requests.get(url,headers=headers) print(re.status_code)#查看請求狀態(tài),返回200說明正常 with open(path, ’wb’) as f:#把圖片數(shù)據(jù)寫入本地,wb表示二進(jìn)制儲存for chunk in re.iter_content(chunk_size=128): f.write(chunk)url=’https://img.ivsky.com/img/tupian/t/201008/05/bianxingjingang-001.jpg’path=’test.jpg’#文件儲存地址get_pictures(url,path)
現(xiàn)在要實(shí)現(xiàn)批量下載圖片,也就是批量獲得圖片的url,那么我們就得分析網(wǎng)頁的代碼結(jié)構(gòu),打開原始網(wǎng)站https://www.ivsky.com/tupian/bianxingjingang_v622/,會看到如下的圖片:
于是我們需要分別得到該頁面中顯示的所有圖片的url,于是我們再次用requests模塊返回當(dāng)前該頁面的內(nèi)容,如下:
import requestsheaders={ ’user-agent’: ’Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3861.400 QQBrowser/10.7.4313.400’}url=’https://www.ivsky.com/tupian/bianxingjingang_v622/’re=requests.get(url,headers=headers)print(re.text)
運(yùn)行會返回當(dāng)前該頁面的網(wǎng)頁結(jié)構(gòu)內(nèi)容,于是我們找到和圖片相關(guān)的也就是.jpg或者.png等圖片格式的字條,如下:

上面圈出來的**//img.ivsky.com/img/tupian/t/201008/05/bianxingjingang-017.jpg**便是我們的圖片url,不過還需要前面加上https:,于是完成的url就是https://img.ivsky.com/img/tupian/t/201008/05/bianxingjingang-017.jpg。
我們知道了這個結(jié)構(gòu),現(xiàn)在就是把這個提取出來,寫個簡單的解析式:
import requestsheaders={ ’user-agent’: ’Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3861.400 QQBrowser/10.7.4313.400’}url=’https://www.ivsky.com/tupian/bianxingjingang_v622/’re=requests.get(url,headers=headers)def get_pictures_urls(text): st=’img src='http://www.leifengta.com.cn/bcjs/’ m=len(st) i=0 n=len(text) urls=[]#儲存url while i<n: if text[i:i+m]==st: url=’’ for j in range(i+m,n):if text[j]==’'’: i=j urls.append(url) breakurl+=text[j] i+=1 return urlsurls=get_pictures_urls(re.text)for url in urls: print(url)
打印結(jié)果如下: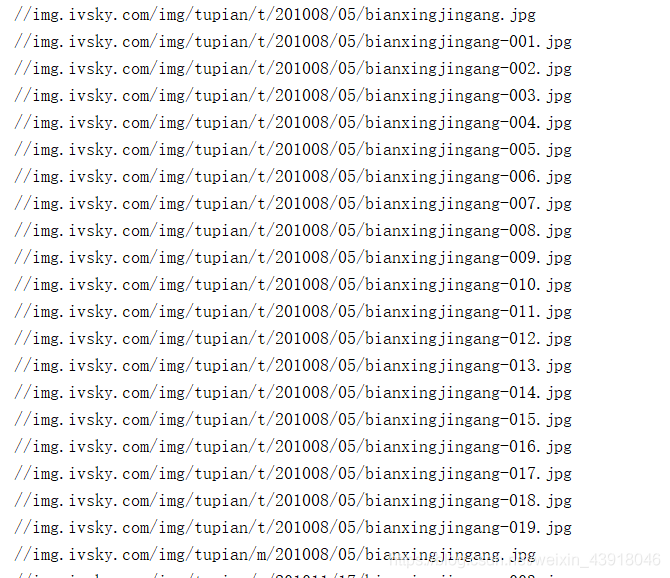
得到了url,現(xiàn)在就直接放入一開始的get_pictures函數(shù)中,爬取圖片辣。
import requestsdef get_pictures(url,path): headers={ ’user-agent’: ’Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3861.400 QQBrowser/10.7.4313.400’} re=requests.get(url,headers=headers) print(re.status_code)#查看請求狀態(tài),返回200說明正常 with open(path, ’wb’) as f:#把圖片數(shù)據(jù)寫入本地,wb表示二進(jìn)制儲存for chunk in re.iter_content(chunk_size=128): f.write(chunk)def get_pictures_urls(text): st=’img src='http://www.leifengta.com.cn/bcjs/’ m=len(st) i=0 n=len(text) urls=[]#儲存url while i<n: if text[i:i+m]==st: url=’’ for j in range(i+m,n):if text[j]==’'’: i=j urls.append(url) breakurl+=text[j] i+=1 return urlsheaders={ ’user-agent’: ’Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3861.400 QQBrowser/10.7.4313.400’}url=’https://www.ivsky.com/tupian/bianxingjingang_v622/’re=requests.get(url,headers=headers)urls=get_pictures_urls(re.text)#獲取當(dāng)前頁面所有圖片的urlfor i in range(len(urls)):#批量爬取圖片 url=’https:’+urls[i] path=’變形金剛’+str(i)+’.jpg’ get_pictures(url,path)
結(jié)果如下:
然后就完成辣,這里只是簡單介紹下批量爬取圖片的過程,具體的網(wǎng)站需要具體分析,所以本文盡可能詳細(xì)的展示了批量爬取圖片的過程分析,希望對你的學(xué)習(xí)有所幫助,如有問題請及時指出,謝謝~
到此這篇關(guān)于Python 爬蟲批量爬取網(wǎng)頁圖片保存到本地的文章就介紹到這了,更多相關(guān)Python 爬蟲爬取圖片保存到本地內(nèi)容請搜索好吧啦網(wǎng)以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持好吧啦網(wǎng)!
相關(guān)文章:
1. php模擬實(shí)現(xiàn)斗地主發(fā)牌2. Python random庫使用方法及異常處理方案3. 理解PHP5中static和const關(guān)鍵字4. spring acegi security 1.0.0 發(fā)布5. Vue封裝一個TodoList的案例與瀏覽器本地緩存的應(yīng)用實(shí)現(xiàn)6. Vuex localStorage的具體使用7. jQuery 實(shí)現(xiàn)DOM元素拖拽交換位置的實(shí)例代碼8. .Net Core使用Coravel實(shí)現(xiàn)任務(wù)調(diào)度的完整步驟9. vue 使用localstorage實(shí)現(xiàn)面包屑的操作10. MyBatis中的JdbcType映射使用詳解

 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備