Python lxml庫的簡單介紹及基本使用講解
lxml是XML和HTML的解析器,其主要功能是解析和提取XML和HTML中的數據;lxml和正則一樣,也是用C語言實現的,是一款高性能的python HTML、XML解析器,也可以利用XPath語法,來定位特定的元素及節點信息
HTML是超文本標記語言,主要用于顯示數據,他的焦點是數據的外觀XML是可擴展標記語言,主要用于傳輸和存儲數據,他的焦點是數據的內容
2.安裝lxml方法方法1:在cmd運行窗口中輸入:pip install lxml
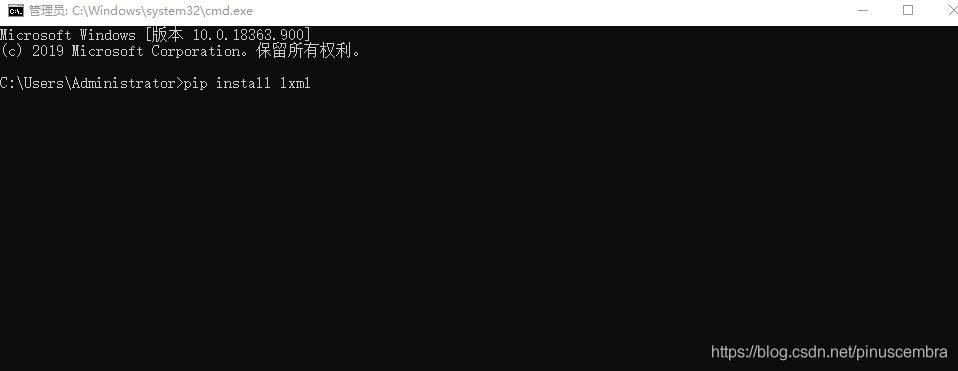
方法2:在Pycharm中下載File?Setting?Project?Project Interpreter?點擊右上角的“+”—第1步
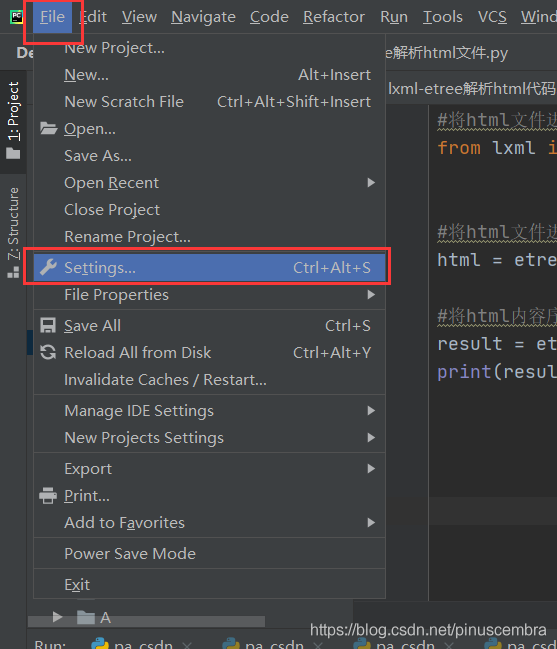
第2步
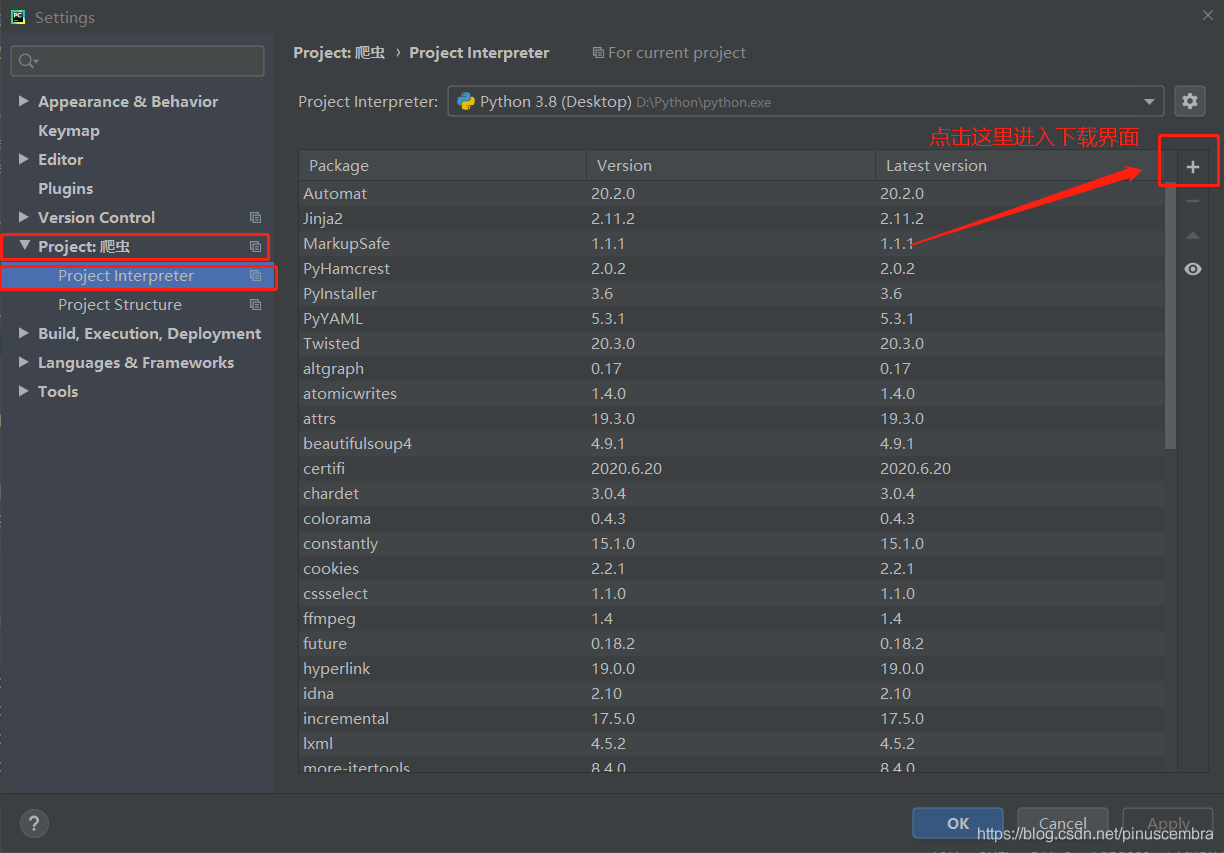
第3步
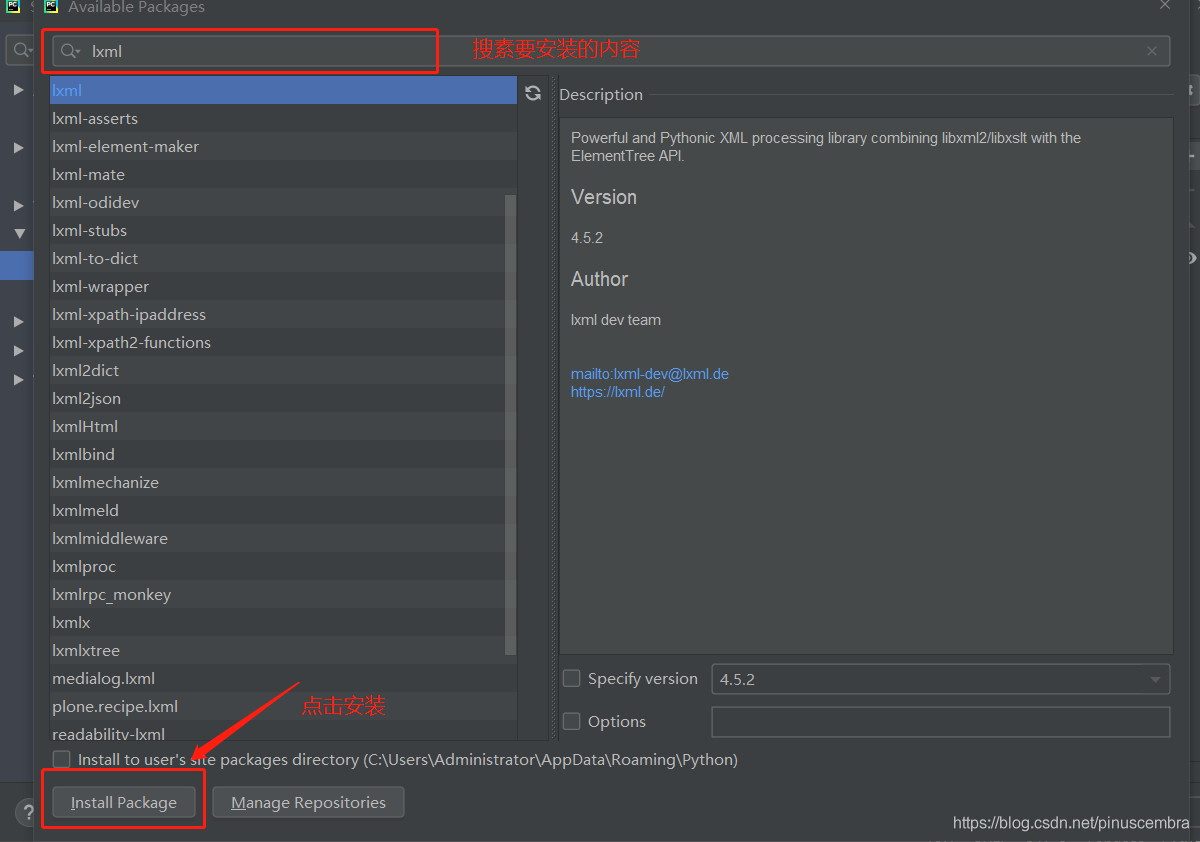
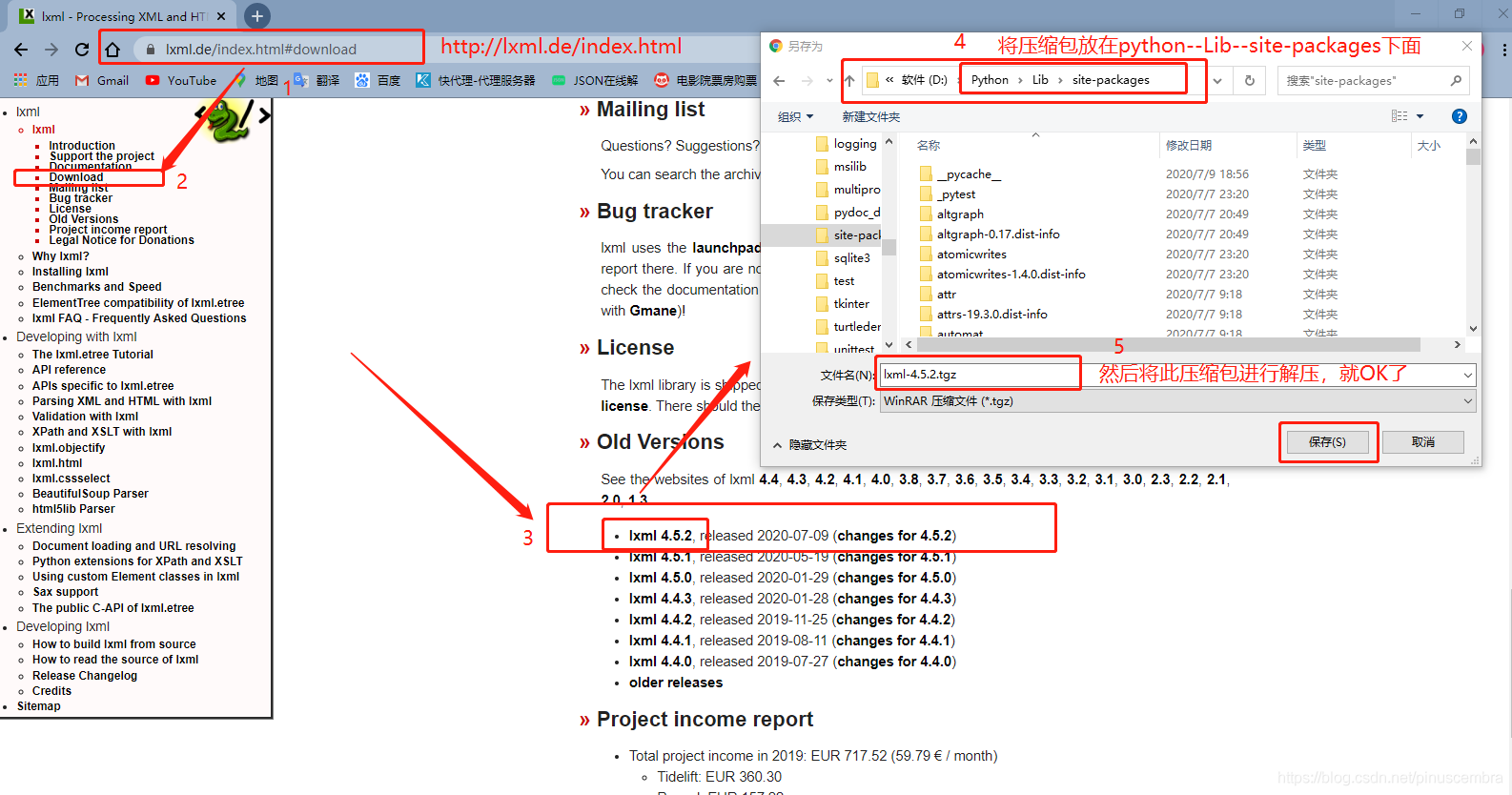
方法3:進入這個網站進行下載:https://lxml.de/index.html
我們可以利用他解析HTML代碼,并且在解析HTML代碼的時候,如果HTML代碼不規范或者不完整,lxml解析器會自動修復或補全代碼,從而提高效率
實例1:解析HTML代碼塊
#提取html中的數據from lxml import etreetext = ’’’<html> <div class='clearfix'> <div class='nav_com'> <ul> <li class='active'><a href='http://www.leifengta.com.cn/' rel='external nofollow' >推薦</a></li> <li class=''><a href='http://www.leifengta.com.cn/nav/python' rel='external nofollow' >Python</a></li> <li class=''><a href='http://www.leifengta.com.cn/nav/java' rel='external nofollow' >Java</a></li> <li class=''><a href='http://www.leifengta.com.cn/nav/web' rel='external nofollow' >前端</a></li> <li class=''><a href='http://www.leifengta.com.cn/nav/arch' rel='external nofollow' >架構</a></li> <li class=''><a href='http://www.leifengta.com.cn/nav/db' rel='external nofollow' >數據庫</a></li> <li class=''><a href='http://www.leifengta.com.cn/nav/5g' rel='external nofollow' >5G</a></li> <li class=''><a href='http://www.leifengta.com.cn/nav/game' rel='external nofollow' >游戲開發</a></li> <li class=''><a href='http://www.leifengta.com.cn/nav/mobile' rel='external nofollow' >移動開發</a></li> <li class=''><a href='http://www.leifengta.com.cn/nav/ops' rel='external nofollow' >運維</a></li> </ul> </div> </div></html>></html>>’’’#將字符串解析為html文檔html = etree.HTML(text)#print(html)#將字符串序列化為htmlresult = etree.tostring(html).decode(’utf-8’)print(result)
實例2:讀取并解析html文件
#將html文件進行解析from lxml import etree#將html文件進行讀取html = etree.parse(’data.html’)#將html內容序列化result = etree.tostring(html).decode(’utf-8’)print(result)
到此這篇關于Python lxml庫的簡單介紹及基本使用講解的文章就介紹到這了,更多相關Python lxml庫使用內容請搜索好吧啦網以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持好吧啦網!
相關文章:
1. Android如何加載Base64編碼格式圖片2. 詳解Android studio 動態fragment的用法3. 解決Android studio xml界面無法預覽問題4. 基于android studio的layout的xml文件的創建方式5. 圖文詳解vue中proto文件的函數調用6. Spring Boot和Thymeleaf整合結合JPA實現分頁效果(實例代碼)7. 什么是python的自省8. 使用Android studio查看Kotlin的字節碼教程9. Vuex localStorage的具體使用10. Vue封裝一個TodoList的案例與瀏覽器本地緩存的應用實現
 網公網安備
網公網安備