Python從文件中讀取數據的方法步驟
一、讀取整個文件內容
在讀取文件之前,我們先創建一個文本文件resource.txt作為源文件。
resource.txt
my name is joker,I am 18 years old,How about you?
如何讀取文件全部內容,我們編寫到reader.py文件中。
reader.py
with open(’resource.txt’) as file_obj: content = file_obj.read() print(content)
需要注意的是需要將resource.txt文件與read.py 放在同一目錄下。
運行后的結果如下:
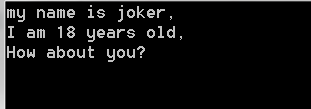
解釋:open函數接收一個參數,此參數為將被讀取內容的文件名,在調用之后返回表示這個文件的對象,Python將之存儲在后面的變量(file_obj)中,關鍵字 with 在我們不再需要使用文件的時候將其關閉。
上面的代碼中open() 函數中傳入的是一個相對路徑,相對路徑會從當前文件(reader.py)所在文件夾下查找指定文件(resource.txt),如果文件不在當前文件夾下,可以使用絕對路徑。Linux系統絕對路徑如:
/home/joker/dic這樣的,Windows系統的絕對路徑如:C:/pyhton_workspace/dic 這樣的。
二、逐行讀取文件內容
file_name = ’resource.txt’ with open(file_name) as file_obj: for content in file_obj: print(content)
控制臺打印如下:
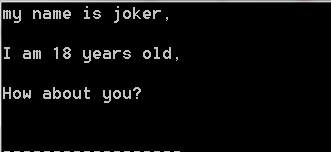
解釋:在上面的程序中,因為Python在讀取文件之后將其存入對象file_obj 中,我們通過對該對象進行循環來遍歷文件中的每一行,但是卻發現,多了空白行,因為在這個文件中,有看不見的換行符,且print語句語句也會加上一個換行符,因此每行的末尾會有兩個換行符。要消除多于的空白行可在print語句中調用rstrip() 方法,如下:
file_name = ’resource.txt’ with open(file_name) as file_obj: for content in file_obj: print(content.rstrip())
控制臺打印如下:
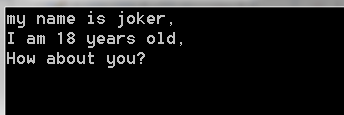
現在,和與讀取整個文件的輸出相同了。
到此這篇關于Python從文件中讀取數據的方法步驟的文章就介紹到這了,更多相關Python 文件讀取數據內容請搜索好吧啦網以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持好吧啦網!
相關文章:

 網公網安備
網公網安備