Mysql數(shù)據(jù)庫設(shè)計三范式實例解析
三范式
1NF:字段不可分;
2NF:有主鍵,非主鍵字段依賴主鍵;
3NF:非主鍵字段不能相互依賴;
解釋:
1NF:原子性 字段不可再分,否則就不是關(guān)系數(shù)據(jù)庫;
2NF:唯一性 一個表只說明一個事物;
3NF:每列都與主鍵有直接關(guān)系,不存在傳遞依賴;
第一范式(1NF)
即表的列的具有原子性,不可再分解,即列的信息,不能分解, 只要數(shù)據(jù)庫是關(guān)系型數(shù)據(jù)庫(mysql/oracle/db2/informix/sysbase/sql server),就自動的滿足1NF。數(shù)據(jù)庫表的每一列都是不可分割的原子數(shù)據(jù)項,而不能是集合,數(shù)組,記錄等非原子數(shù)據(jù)項。如果實體中的某個屬性有多個值時,必須拆分為不同的屬性 。通俗理解即一個字段只存儲一項信息。
關(guān)系型數(shù)據(jù)庫: mysql/oracle/db2/informix/sysbase/sql server 非關(guān)系型數(shù)據(jù)庫: (特點: 面向?qū)ο蠡蛘呒? NoSql數(shù)據(jù)庫: MongoDB/redis(特點是面向文檔)
第二范式(2NF)
第二范式(2NF)是在第一范式(1NF)的基礎(chǔ)上建立起來的,即滿足第二范式(2NF)必須先滿足第一范式(1NF)。第二范式(2NF)要求數(shù)據(jù)庫表中的每個實例或行必須可以被惟一地區(qū)分。為實現(xiàn)區(qū)分通常需要我們設(shè)計一個主鍵來實現(xiàn)(這里的主鍵不包含業(yè)務(wù)邏輯)。
即滿足第一范式前提,當存在多個主鍵的時候,才會發(fā)生不符合第二范式的情況。比如有兩個主鍵,不能存在這樣的屬性,它只依賴于其中一個主鍵,這就是不符合第二范式。通俗理解是任意一個字段都只依賴表中的同一個字段。(涉及到表的拆分)
看下面的學(xué)生選課表:
學(xué)號 課程 成績 課程學(xué)分 10001 數(shù)學(xué) 100 6 10001 語文 90 2 10001 英語 85 3 10002 數(shù)學(xué) 90 6 10003 數(shù)學(xué) 99 6 10004 語文 89 2
表中主鍵為 (學(xué)號,課程),我們可以表示為 (學(xué)號,課程) -> (成績,課程學(xué)分), 表示所有非主鍵列 (成績,課程學(xué)分)都依賴于主鍵 (學(xué)號,課程)。 但是,表中還存在另外一個依賴:(課程)->(課程學(xué)分)。這樣非主鍵列 ‘課程學(xué)分‘ 依賴于部分主鍵列 ’課程‘, 所以上表是不滿足第二范式的。
我們把它拆成如下2張表:
學(xué)生選課表:
學(xué)號 課程 成績 10001 數(shù)學(xué) 100 10001 語文 90 10001 英語 85 10002 數(shù)學(xué) 90 10003 數(shù)學(xué) 99 10004 語文 89
課程信息表:
課程 課程學(xué)分 數(shù)學(xué) 6 語文 3 英語 2
那么上面2個表,學(xué)生選課表主鍵為(學(xué)號,課程),課程信息表主鍵為(課程),表中所有非主鍵列都完全依賴主鍵。不僅符合第二范式,還符合第三范式。
再看這樣一個學(xué)生信息表:
學(xué)號 姓名 性別 班級 班主任 10001 張三 男 一班 小王 10002 李四 男 一班 小王 10003 王五 男 二班 小李 10004 張小三 男 二班 小李
上表中,主鍵為:(學(xué)號),所有字段 (姓名,性別,班級,班主任)都依賴與主鍵(學(xué)號),不存在對主鍵的部分依賴。所以是滿足第二范式。
第三范式(3NF)
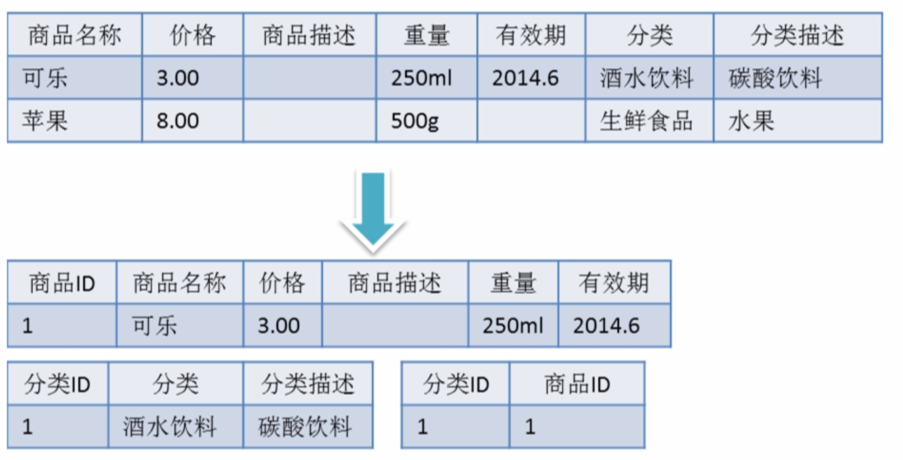
滿足第三范式(3NF)必須先滿足第二范式(2NF)。簡而言之,第三范式(3NF)要求一個數(shù)據(jù)庫表中不包含已在其它表中已包含的非主鍵字段。就是說,表的信息,如果能夠被推導(dǎo)出來,就不應(yīng)該單獨的設(shè)計一個字段來存放(能盡量外鍵join就用外鍵join)。很多時候,我們?yōu)榱藵M足第三范式往往會把一張表分成多張表。
即滿足第二范式前提,如果某一屬性依賴于其他非主鍵屬性,而其他非主鍵屬性又依賴于主鍵,那么這個屬性就是間接依賴于主鍵,這被稱作傳遞依賴于主屬性。 通俗解釋就是一張表最多只存兩層同類型信息。
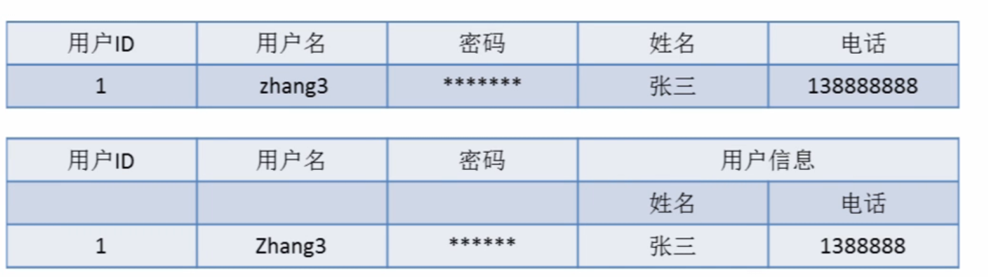
反三范式
沒有冗余的數(shù)據(jù)庫未必是最好的數(shù)據(jù)庫,有時為了提高運行效率,提高讀性能,就必須降低范式標準,適當保留冗余數(shù)據(jù)。具體做法是: 在概念數(shù)據(jù)模型設(shè)計時遵守第三范式,降低范式標準的工作放到物理數(shù)據(jù)模型設(shè)計時考慮。降低范式就是增加字段,減少了查詢時的關(guān)聯(lián),提高查詢效率,因為在數(shù)據(jù)庫的操作中查詢的比例要遠遠大于DML的比例。但是反范式化一定要適度,并且在原本已滿足三范式的基礎(chǔ)上再做調(diào)整的。
以上就是本文的全部內(nèi)容,希望對大家的學(xué)習(xí)有所幫助,也希望大家多多支持好吧啦網(wǎng)。
相關(guān)文章:
1. DB2 與 Microsoft SQL Server 2000 之間的 SQL 數(shù)據(jù)復(fù)制2. 細化解析:Oracle 10g ASM 的一點經(jīng)驗3. DB2 XML 全文搜索之為文本搜索做準備4. MySQL InnoDB架構(gòu)的相關(guān)總結(jié)5. MyBatis中$和#的深入講解6. Mysql InnoDB和MyISAM區(qū)別原理解析7. 國內(nèi)學(xué)院派專家對DB2 9新產(chǎn)品贊不絕口8. 解讀Oracle中代替like進行模糊查詢的方法instr(更高效)9. mysql中使用date_add()函數(shù)講解10. 簡單了解mysql InnoDB MyISAM相關(guān)區(qū)別

 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備