Python scrapy爬取小說(shuō)代碼案例詳解
scrapy是目前python使用的最廣泛的爬蟲(chóng)框架
架構(gòu)圖如下
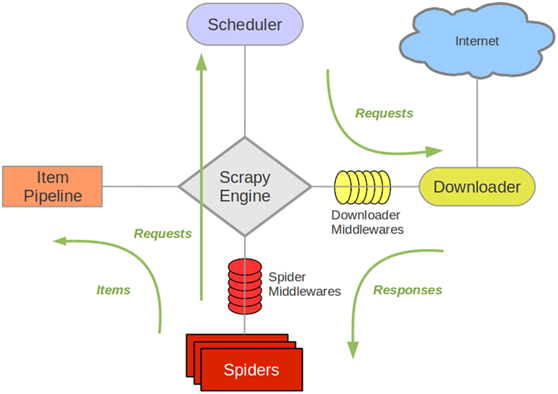
解釋?zhuān)?/p> Scrapy Engine(引擎): 負(fù)責(zé)Spider、ItemPipeline、Downloader、Scheduler中間的通訊,信號(hào)、數(shù)據(jù)傳遞等。 Scheduler(調(diào)度器): 它負(fù)責(zé)接受引擎發(fā)送過(guò)來(lái)的Request請(qǐng)求,并按照一定的方式進(jìn)行整理排列,入隊(duì),當(dāng)引擎需要時(shí),交還給引擎。 Downloader(下載器):負(fù)責(zé)下載Scrapy Engine(引擎)發(fā)送的所有Requests請(qǐng)求,并將其獲取到的Responses交還給Scrapy Engine(引擎),由引擎交給Spider來(lái)處理, Spider(爬蟲(chóng)):它負(fù)責(zé)處理所有Responses,從中分析提取數(shù)據(jù),獲取Item字段需要的數(shù)據(jù),并將需要跟進(jìn)的URL提交給引擎,再次進(jìn)入Scheduler(調(diào)度器), Item Pipeline(管道):它負(fù)責(zé)處理Spider中獲取到的Item,并進(jìn)行進(jìn)行后期處理(詳細(xì)分析、過(guò)濾、存儲(chǔ)等)的地方. DownloaderMiddlewares(下載中間件):你可以當(dāng)作是一個(gè)可以自定義擴(kuò)展下載功能的組件。Spider Middlewares(Spider中間件):你可以理解為是一個(gè)可以自定擴(kuò)展和操作引擎和Spider中間通信的功能組件(比如進(jìn)入Spider的Responses;和從Spider出去的Requests
一。安裝
pip install Twisted.whl
pip install Scrapy
Twisted的版本要與安裝的python對(duì)應(yīng),https://jingyan.baidu.com/article/1709ad8027be404634c4f0e8.html
二。代碼
本實(shí)例采用xpaths解析頁(yè)面數(shù)據(jù)
按住shift-右鍵-在此處打開(kāi)命令窗口
輸入scrapy startproject qiushibaike 創(chuàng)建項(xiàng)目
輸入scrapy genspiderqiushibaike 創(chuàng)建爬蟲(chóng)
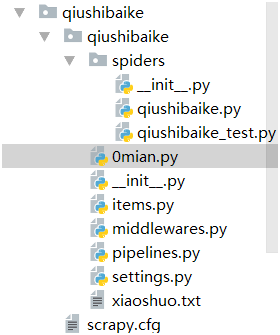
1>結(jié)構(gòu)
2>qiushibaike.py爬蟲(chóng)文件
import scrapyfrom scrapy.linkextractors import LinkExtractorfrom scrapy.spiders.crawl import Rule, CrawlSpiderclass BaiduSpider(CrawlSpider): name = ’qiushibaike’ allowed_domains = [’qiushibaike.com’] start_urls = [’https://www.qiushibaike.com/text/’]#啟始頁(yè)面# rules= ( Rule(LinkExtractor(restrict_xpaths=r’//a[@class='contentHerf']’),callback=’parse_item’,follow=True), Rule(LinkExtractor(restrict_xpaths=r’//ul[@class='pagination']/li/a’),follow=True) ) def parse_item(self, response): title=response.xpath(’//h1[@class='article-title']/text()’).extract_first().strip() #標(biāo)題 time=response.xpath(’ //span[@class='stats-time']/text()’).extract_first().strip() #發(fā)布時(shí)間 content=response.xpath(’//div[@class='content']/text()’).extract_first().replace(’’,’n’) #內(nèi)容 score=response.xpath(’//i[@class='number']/text()’).extract_first().strip() #好笑數(shù) yield({'title':title,'content':content,'time':time,'score':score});
3>pipelines.py 數(shù)據(jù)管道[code]class QiushibaikePipeline:
class QiushibaikePipeline: def open_spider(self,spider):#啟動(dòng)爬蟲(chóng)中調(diào)用 self.f=open('xiaoshuo.txt','w',encoding=’utf-8’) def process_item(self, item, spider): info=item.get('title')+'n'+ item.get('time')+' 好笑數(shù)'+item.get('score')+'n'+ item.get('content')+’n’ self.f.write(info+'n') self.f.flush() def close_spider(self,spider):#關(guān)閉爬蟲(chóng)中調(diào)用 self.f.close()
4>settings.py
開(kāi)啟ZhonghengPipeline
ITEM_PIPELINES = { ’qiushibaike.pipelines.QiushibaikePipeline’: 300,}
5>0main.py運(yùn)行
from scrapy.cmdline import executeexecute(’scrapy crawl qiushibaike’.split())
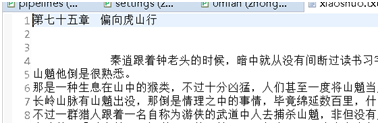
6>結(jié)果:
生成xiaohua.txt,里面有下載的笑話文字
以上就是本文的全部?jī)?nèi)容,希望對(duì)大家的學(xué)習(xí)有所幫助,也希望大家多多支持好吧啦網(wǎng)。
相關(guān)文章:
1. PHP輸入流php://input的使用分析2. Django項(xiàng)目如何正確配置日志(logging)3. PHP與MYSQL數(shù)據(jù)庫(kù)連接4. 利用Java對(duì)PDF文件進(jìn)行電子簽章的實(shí)戰(zhàn)過(guò)程5. asp文件用什么軟件編輯6. PHP基礎(chǔ)之生成器4——比較生成器和迭代器對(duì)象7. ASP新手必備的基礎(chǔ)知識(shí)8. CentOS郵箱服務(wù)器搭建系列——SMTP服務(wù)器的構(gòu)建( Postfix )9. 詳解PHP laravel中的加密與解密函數(shù)10. Docker 啟動(dòng)Redis 并設(shè)置密碼的操作

 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備