SQL Server實(shí)現(xiàn)group_concat功能的詳細(xì)實(shí)例
目錄
- 一、實(shí)現(xiàn)
- 二、原理分析
- 2.1、FOR XML PATH的作用
- 2.2、STUFF函數(shù)
- 2.2.1、STUFF函數(shù)在本SQL的作用
- 2.2.2、STUFF函數(shù)語法
- 2.3、sql語分分析
- 2.3.1、一個簡單的group by
- 2.3.2、在select語句后面加上子查詢
- 2.3.3、去掉子查詢結(jié)果集的第一個分隔符
- 總結(jié)
一、實(shí)現(xiàn)
#tmp表內(nèi)容如下:
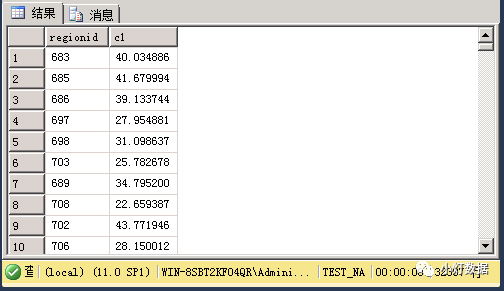
實(shí)現(xiàn)group_concat的sql語句為:
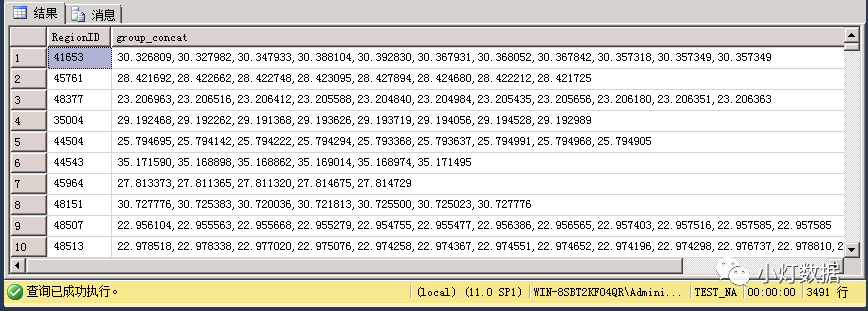
Select RegionID, STUFF( ( SELECT "," + T.c1 FROM #tmp T WHERE A.regionid = T.regionid FOR XML PATH("") ), 1, 1, "" ) as group_concat FROM #tmp AGroup by RegionID實(shí)現(xiàn)效果如下:
二、原理分析
2.1、FOR XML PATH的作用
FOR XML PATH 的作用是將查詢結(jié)果集以XML形式展現(xiàn),將多行的結(jié)果,展示在同一行,例如:
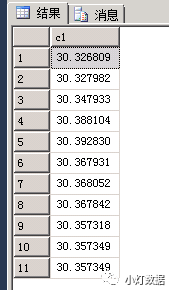
select c1 from #tmp where RegionID = 41653
其結(jié)果集如下:
select c1 from #tmp where RegionID = 41653 FOR XML PATH("")當(dāng)sql語句加上 FOR XML PATH('') 后,其結(jié)果集輸出是:
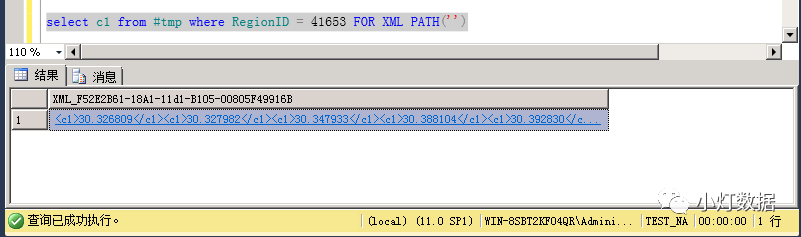
具體輸出的字符如下:
<c1>30.326809</c1><c1>30.327982</c1><c1>30.347933</c1><c1>30.388104</c1><c1>30.392830</c1><c1>30.367931</c1><c1>30.368052</c1><c1>30.367842</c1><c1>30.357318</c1><c1>30.357349</c1><c1>30.357349</c1>
通過字符拼接后可以把xml信息清除,并以指定的字符進(jìn)行分割:
select "," + c1 from #tmp where RegionID = 41653 FOR XML PATH("")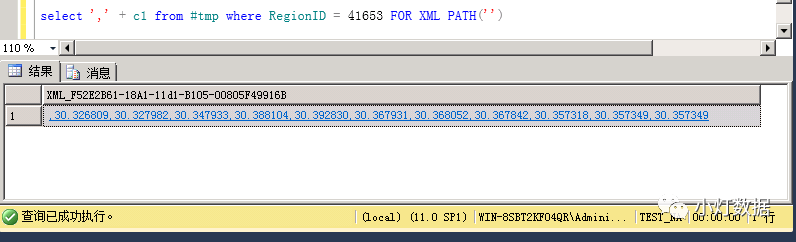
此時已基本達(dá)到group_concat的效果,但第一個字符串有分隔符需要去掉。
2.2、STUFF函數(shù)
2.2.1、STUFF函數(shù)在本SQL的作用
我們使用STUFF函數(shù)的目的是把第一個分隔符去掉。先看看效果:
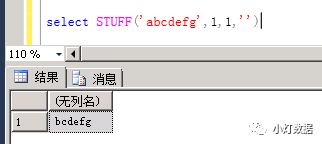
上圖可以看到,STUFF函數(shù)把字符串“abcdefg”中的第一個字符“a”刪除。
使用該函數(shù)我們可以很輕松的把上圖得到的結(jié)果集去掉第一個逗號分隔符:
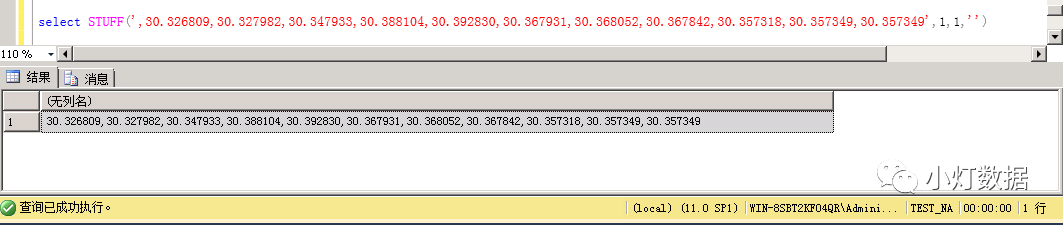
需要詳細(xì)了解STUFF函數(shù)可繼續(xù)看該函數(shù)的語法,沒興趣的可以忽略。
2.2.2、STUFF函數(shù)語法
STUFF函數(shù)的作用是將字符串插入到另一個字符串中。它從第一個字符串的開始位置刪除指定長度的字符,然后將第二個字符串插入到第一個字符串的開始位置。其語法為:
STUFF(character_expression , start , length , replaceWith_expression)
character_expression:字符數(shù)據(jù)的表達(dá)式,可以是常量、變量,也可以是字符列或二進(jìn)制數(shù)據(jù)列。
start:一個整數(shù)值(從1開始),指定刪除和插入的開始位置。start的類型可以是bigint。
• 如果 start 為負(fù)或?yàn)榱悖瑒t返回空字符串。
• 如果 start 的長度大于第一個 character_expression,則返回空字符串。
length:一個整數(shù),指定要刪除的字符數(shù)。length的類型可以是 bigint。
• 如果 length 為負(fù),則返回空字符串。
• 如果 length 的長度大于character_expression,則最多可以刪除到character_expression 中的最后一個字符。
• 如果 length 為零,則不刪除字符直接在指定位置插入內(nèi)容。
replaceWith_expression:字符數(shù)據(jù)的表達(dá)式,可以是常量、變量,也可以是字符列或二進(jìn)制數(shù)據(jù)列。此表達(dá)式從 start 開始替換 length 個字符的character_expression。
• 如果 replaceWith_expression 為 NULL,則在不插入任何內(nèi)容的情況下刪除字符。
2.3、sql語分分析
2.3.1、一個簡單的group by
Select RegionID FROM #tmp AGroup by RegionID
這個sql各位看官都十分熟悉,已經(jīng)沒什么好說的了。
2.3.2、在select語句后面加上子查詢
Select RegionID, ( SELECT "," + T.c1 FROM #tmp T WHERE A.regionid = T.regionid FOR XML PATH("") ) FROM #tmp AGroup by RegionID在上述簡單的group by語句基礎(chǔ)上加入一個select里的子查詢,其結(jié)果如下:
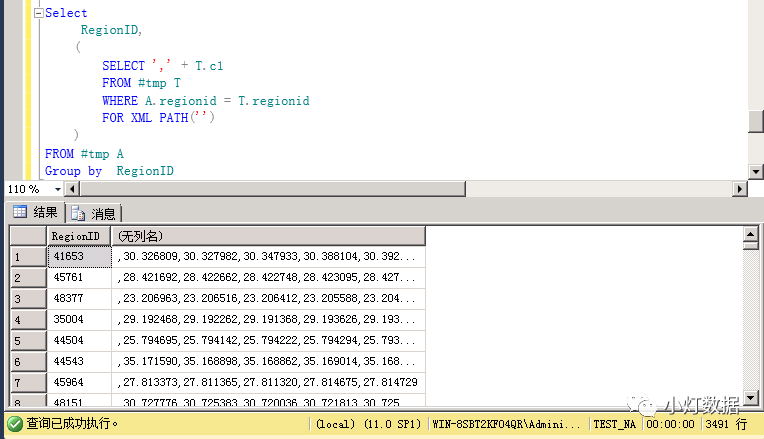
在該子查詢中,當(dāng)外層的group by返回結(jié)果集中的第一行RegionID為41653時,這個值被子查詢的where條件所使用,相當(dāng)于:
SELECT "," + T.c1FROM #tmp TWHERE T.regionid = 41653FOR XML PATH("")因?yàn)镕OR XML PATH把多行記錄打平成一條記錄,因此此時的返回結(jié)果為:
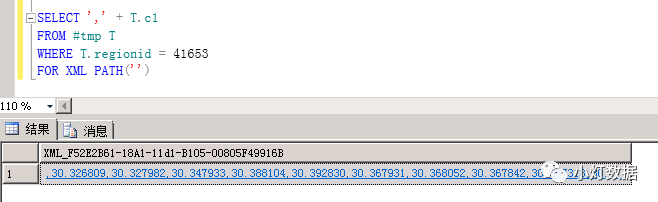
接著第group by返回結(jié)果集中的第二行45761傳入該子查詢,依次類似上面描述的執(zhí)行,直到所有外層的值遍歷完成。
2.3.3、去掉子查詢結(jié)果集的第一個分隔符
Select RegionID, STUFF( ( SELECT "," + T.c1 FROM #tmp T WHERE A.regionid = T.regionid FOR XML PATH("") ), 1, 1, "" ) as group_concat FROM #tmp AGroup by RegionID利用STUFF函數(shù),去掉了第一個逗號,完成了最終sql語句。
總結(jié)
到此這篇關(guān)于SQL Server實(shí)現(xiàn)group_concat功能的文章就介紹到這了,更多相關(guān)SQLServer實(shí)現(xiàn)group_concat內(nèi)容請搜索以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持!
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備